

分享
'%3e%3cpath%20d='M12.8276%205.73367L12.5096%208.74976H10.0987V17.4995H6.47736V8.74976H4.67285V5.73367H6.47736V3.91783C6.47736%201.46481%207.49748%200%2010.3973%200H12.807V3.01609H11.299C10.1739%203.01609%2010.0987%203.44123%2010.0987%204.22665V5.73367H12.8276Z'%20fill='%2398A2B3'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_162_3194'%3e%3crect%20width='17.4995'%20height='17.4995'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M6.91992,6l14.2168,20.72656l-14.9082,17.27344h3.17773l13.13867,-15.22266l10.44141,15.22266h10.01367l-14.87695,-21.6875l14.08008,-16.3125h-3.17578l-12.31055,14.26172l-9.7832,-14.26172z'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
告別延遲!單鏡頭人體網格重建大突破,IDEA 發表 PEAR 模型讓虛擬分身「隨心而動」

想像一個場景:一位專門受訓地震的消防人員,面前有一台普通的網路攝影機和一面大螢幕,螢幕裡面有一個正在模擬大地震的虛擬城市,同時也有一個一模一樣的虛擬人物,消防人員只要舉手、蹲下、轉身不管什麼動作,都可以一模一樣的呈現在虛擬當中。這不是什麼科幻電影的場景,而是單鏡頭人體網格重建(Monocular Human Mesh Recovery,HMR)技術正在讓它成為真正的事情。
甚麼是人體網格重建?簡單來說,就是從RGB影像推估人體完整的3D姿勢與體型,產生一個可以拿來做分析,甚至是即時驅動數位虛擬人的模型。聽起來好像很簡單且蠻容易聯想,但是卻非常困難,從一張2D圖像中要做到這些技術,會遇到包括缺乏深度資訊、缺乏手指跟臉的精細部位、容易被遮擋或是模糊等挑戰。在過去研究者只能大概推估身體的骨架的SMPL模型(Skinned Multi-Person Linear model),隨著時間跟技術的發展,已經發展到可以同時處理手、表情、等精細的部份的SMPL-X的參數人體模型,但隨著精度越來越高,在速度跟實用性上面,還是遇到很大的瓶頸。
在今(2026)年終於有新的突破,其中一個代表性的框架模型-PEAR(Pixel-aligned Expressive humAn mesh Recovery)誕生了!PEAR由國際數位經濟學院(International Digital Economy Academy,IDEA)在2026年初發表,他的做法跟以往不太一樣,只用了一個輕量的VIT-B的骨幹模型,透過單次推論就能同時輸出身體姿態、手部動作和臉部表情的參數。
根據論文實測, PEAR 每秒可以處理約 100 張畫面,比過去主流的方法快了 5 到 10 倍,甚至比一般網路攝影機拍攝的速度還快,完全跟得上即時同步的需求,因為不需要在前處理的時候使用其他模型,把手跟臉辨識出來,透過單次推論就可以完成全身的網格重建,速度上非常的快。
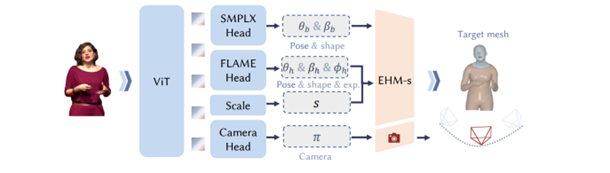
圖1:PEAR架構模型圖
資料來源: https://arxiv.org/abs/2601.22693
PEAR能這麼快的又這麼準,是因為提出一套分析到合成的訓練方式,第一階段先讓模型從單偵影像學會回歸人體參數,第二階段再引入神經渲染,用影片中的連續畫面對讓渲染結果和原始影像做像素級的比對。這種密集的視覺回饋訊號,能在不拖慢推論速度的前提下,大幅改善嘴唇、手指尖端等容易出錯的精細區域。
此外,PEAR把身體、手部、頭部的標註分開處理,讓模型就算只拿到上半身或臉部特寫的訓練資料,也能穩定學習,不會因為輸入條件不同就崩潰。在這個研究之下還有很多值得關注的一些專案,例如SMPLest-X是SMPLer-X的優化版本,他們是專注在用更大的模型去做更精細的方法,也有很多方法像是SAM 3D Body、MetricHMR都是不錯的專案。
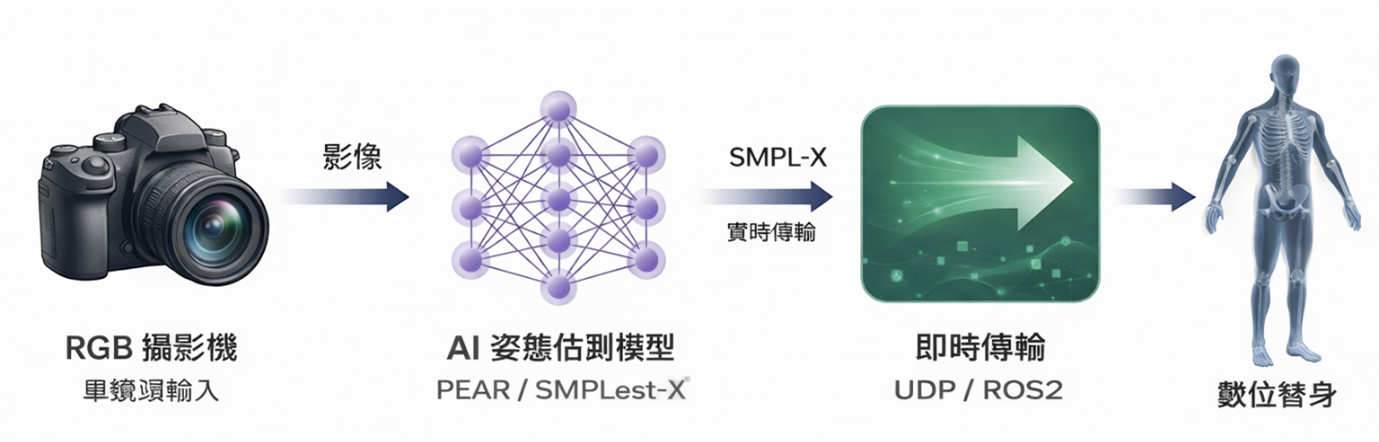
圖2:單鏡頭人體網格重建整合至Unity數位雙生場景的概念架構圖
資料來源:本作者透過ChatGPT Canvas工具製圖
這些技術進展讓數位雙生的建置門檻大幅降低,以往要讓虛擬角色跟著真人動,通常需要穿戴式感測器或昂貴的多鏡頭光學動捕系統,現在只要一臺網路攝影機就能做到精細的方式。同時也可以應用於不同場域中,包括在防災教育訓練中,受訓者可以用自然的肢體動作與虛擬災害場景進行互動;在工廠製造產線上,單鏡頭可以持續監測作業人員的姿態,偵測不安全行為並進一步預測職業傷害風險發生;在展覽或表演場域,觀眾的肢體動作可以即時驅動互動裝置,不需要穿戴任何額外的設備。
當然,目前階段這些技術也還是會有一些限制,像是遮擋嚴重、光線不佳或多人重疊的情況下,品質有時候會降低,而且如何在邊緣裝置上部署這些模型,以及如何確保輸出的動作資料能跨平台使用,也都是實際落地後要解決的工程問題。不過,隨著模型持續輕量化、SMPL-X的生態系的再慢慢的成熟,之後人人都可以使用一臺攝影機以及一臺電腦,就能建立人體數位分身的應用情境,已經不再是遙遠的夢想。
封面圖片來源:本作者透過ChatGPT Canvas工具製圖
參考資料來源:
1. Wu et al., PEAR: Pixel-aligned Expressive humAn mesh Recovery, arXiv:2601.22693v2, 2026:https://arxiv.org/abs/2601.22693
2. Yin et al., SMPLest-X: Ultimate Scaling for Expressive Human Pose and Shape Estimation, IEEE TPAMI, 2025:https://github.com/SMPLCap/SMPLest-X
3. Yang et al., Fast SAM 3D Body: Accelerating SAM 3D Body for Real-Time Full-Body Human Mesh Recovery, arXiv:2603.15603, 2026:https://arxiv.org/abs/2603.15603
4. Song et al., MetricHMSR: Metric Human Mesh and Scene Recovery from Monocular Images, CVPR 2026:https://arxiv.org/abs/2506.09919
5. Training First Responders Through VR-Based Situated Digital Twins, MDPI Computers, 2025:https://www.mdpi.com/2073-431X/14/7/274
6. Virtual Reality and Digital Twins for Catastrophic Failure Prevention in Industry 4.0, MDPI Applied Sciences, 2025:https://www.mdpi.com/2076-3417/15/13/7230
林晏寬
2026-05-06
