

分享
'%3e%3cpath%20d='M12.8276%205.73367L12.5096%208.74976H10.0987V17.4995H6.47736V8.74976H4.67285V5.73367H6.47736V3.91783C6.47736%201.46481%207.49748%200%2010.3973%200H12.807V3.01609H11.299C10.1739%203.01609%2010.0987%203.44123%2010.0987%204.22665V5.73367H12.8276Z'%20fill='%2398A2B3'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_162_3194'%3e%3crect%20width='17.4995'%20height='17.4995'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M6.91992,6l14.2168,20.72656l-14.9082,17.27344h3.17773l13.13867,-15.22266l10.44141,15.22266h10.01367l-14.87695,-21.6875l14.08008,-16.3125h-3.17578l-12.31055,14.26172l-9.7832,-14.26172z'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
VTuber技術演進觀測:從即時追蹤到AI生成角色(下)
上篇我們針對角色製作與即時追蹤等兩大VTuber系統技術與工具進行探討,本篇將進一步就VTuber角色AI生成相關技術與系統進行介紹。
【AI 生成VTuber的技術現況】
以「AI生成VTuber」為名的線上服務逐漸增多,但從實際功能檢視後可以發現,目前市面上多數服務的能力仍集中在「VTuber風格的角色插畫生成」,而非真正能輸出可驅動模型的工具。例如Fotor與Phot.AI都以「AI VTuber Maker」作為產品名稱,並在頁面上列出2D、3D VTuber角色生成等說法,但實際輸出的內容多為單張角色圖片,並不含Live2D所需的分層資訊,也沒有 VRM 模型必備的骨架、權重與BlendShape。因此,這些工具雖能在設計階段提供視覺草稿與風格探索,但與VTuber製作流程中「模型構建、裝配與驅動」等關鍵步驟仍有明顯差距。
目前未見公開案例能證實使用這類AI服務便能直接獲得可在VTube Studio或VSeeFace中運作的模型,使用者回饋也多半指出生成內容仍需大量後製才能實際使用。現階段AI在VTuber領域的角色主要仍侷限於「前期視覺設計輔助」:提供角色概念草稿、嘗試不同服飾造型、協助貼圖風格統一等。在模型製作、骨架綁定與即時驅動方面,仍必須仰賴現有工具與人工流程,尚不存在可完整自動化VTuber模型的生成技術。
AI生成VTuber目前仍屬於「輔助式設計工具」階段,能降低角色前期視覺設計的門檻與製作時間,但距離真正能輸出可用於直播或互動展演的 VTuber 模型仍有明顯技術差距。未來若生成式模型在分層理解、3D拓撲與骨架生成方面取得進展,才有可能推動VTuber模型製作流程的更高程度自動化。
我們以Fotor AI VTuber Maker為例,介紹聲稱能夠生成Vtuber服務。Fotor所提供的「AI VTuber Maker」在功能上主要聚焦於產生VTuber風格的角色插畫,而非完整的模型製作與驅動流程。此服務可透過文字描述快速生成角色造型,包含髮型、服裝與背景等元素,適合作為角色企劃階段的視覺草稿或風格參考。實際使用者也普遍將其視為一種「快速構思角色外觀」的方式,而非最終可直接投入VTuber製作的素材。

圖1 Fotor 官方「AI VTuber Maker」產品頁
資料來源: Fotor 官方網頁
此外,市面上其他以「AI VTuber Maker」或類似名稱作為產品亮點的線上服務,多半也呈現相同的情況:雖然宣稱能以AI生成VTuber角色,但實際提供的仍是VTuber風格的2D圖像,並未包含能夠直接投入VTuber製作流程的分層資訊、骨架設定或可驅動模型格式。這些服務普遍著重於快速生成外觀草稿或服飾方案,而非真正的模型構建,因此在實務上仍屬於前期視覺設計階段的輔助工具。對於需要建立可於VTube Studio、VSeeFace或其他驅動軟體中使用的實際 VTuber 模型,仍需經由傳統 Live2D 製作或手動建模流程完成。
【未來展望:AI生成VTuber素材與模型的可能性】
雖然目前的AI技術仍無法直接生成可用於VTuber的完整模型,但從相關研究與工具的發展趨勢來看,未來仍具有相當大的進步空間。要讓AI真正能協助建立Live2D或3D VTuber模型,首先必須克服「結構理解」與「分層邏輯」這兩項核心難題。現今的影像生成模型雖能產出高品質插畫,但並不具備解析角色結構、預測遮擋部位或規劃可動元素的能力。因此,即便生成結果符合VTuber的視覺風格,其內容仍無法直接用於rigging或模型驅動。
在2D VTuber的製作流程中,角色的不同部位具有非常明確的結構與變形需求,例如眼睛需要具備眨眼、瞇眼、微笑等多種變化,嘴巴必須對應張口、唇形與表情,髮型則涉及飄動與層次,臉型在不同角度下也必須保持一致。因此,未來AI若要更深入參與VTuber的素材生成,有可能採取「由整體模型拆分為多個小模型」的方式,針對這些角色部位分別進行訓練與生成。
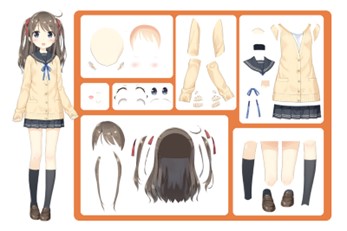
圖2 分層素材,包含髮型、臉、耳朵、衣服等各部件 2D 模型師常用的切片形式
資料來源: Live2D 官方教學網頁
例如,模型可以專門學習眼睛在不同表情與角度下的形狀變化,另一個模型負責嘴形與口部結構,而髮型或臉部輪廓也可使用獨立的資料進行訓練。這種做法的好處是,VTuber 所需的素材其實具有高度重複特性:大多數眼睛與嘴型的變化模式相似、髮絲的層次結構常見、而臉部輪廓的推斷也可依靠大量角色資料進行統計建模。若AI能在這些局部部位上建立較高品質的生成能力,就有機會提供可直接使用或較易編修的素材,降低 Live2D 的前置製作成本。
然而,這樣的模型要真正整合成可用於VTuber的完整素材,仍需要解決「部位之間的一致性」問題。例如眼睛與臉型比例必須始終匹配、頭髮的角度需要與頭部旋轉同步、不同角度的嘴形必須能與rigging邏輯對應等。未來若能將局部部位的生成模型與整體角色的一致性檢查或多視角對齊技術結合,便有可能在素材層級上達到更高程度的自動化,進一步應用到Live2D或VTuber模型的製作流程中。
觀察AI在VTuber創作的技術發展,在製作流程中的角色將逐漸從「前期素材輔助」走向「半自動化建模」,最終甚至可能達到「從文本生成可驅動角色」的全流程自動化。但這仍需要資料集、模型架構與產業需求的共同成熟。在此之前,AI所能扮演的仍是輔助創作者提高效率的夥伴,而非取代模型師的完整解決方案。然而,隨著生成式技術持續進化,未來的VTuber製作流程勢必會更加快速、模組化、並具備更高程度的自動化,為虛擬角色產業帶來新一波創作可能性。
封面圖片來源:https://www.live2d.com/zh-CHS/cubism/comparison/
參考資料來源:
- Live2D官方youtube影片:https://www.youtube.com/watch?v=XW6Yrxnn5dM
- VRoid Studio 官方頁面:https://vroid.com/en/studio?utm_source=chatgpt.com
- VTube Studio 官方GitHub Wiki頁面:https://github.com/DenchiSoft/VTubeStudio/wiki/VTube-Studio-Settings
- VSeeFace 官方網站「Help & FAQ」:https://www.vseeface.icu/
- Fotor 官方「AI VTuber Maker」產品頁:https://www.fotor.com/features/ai-vtuber-maker/%EF%BC%89
- Live2D 官方教學網頁:https://docs.live2d.com/cubism-editor-manual/divide-the-material/
郭力瑋
2025-12-09
