

分享
'%3e%3cpath%20d='M12.8276%205.73367L12.5096%208.74976H10.0987V17.4995H6.47736V8.74976H4.67285V5.73367H6.47736V3.91783C6.47736%201.46481%207.49748%200%2010.3973%200H12.807V3.01609H11.299C10.1739%203.01609%2010.0987%203.44123%2010.0987%204.22665V5.73367H12.8276Z'%20fill='%2398A2B3'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_162_3194'%3e%3crect%20width='17.4995'%20height='17.4995'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M6.91992,6l14.2168,20.72656l-14.9082,17.27344h3.17773l13.13867,-15.22266l10.44141,15.22266h10.01367l-14.87695,-21.6875l14.08008,-16.3125h-3.17578l-12.31055,14.26172l-9.7832,-14.26172z'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
告別碎片化工具!多模態AI全面崛起,企業AI部署策略正在翻轉
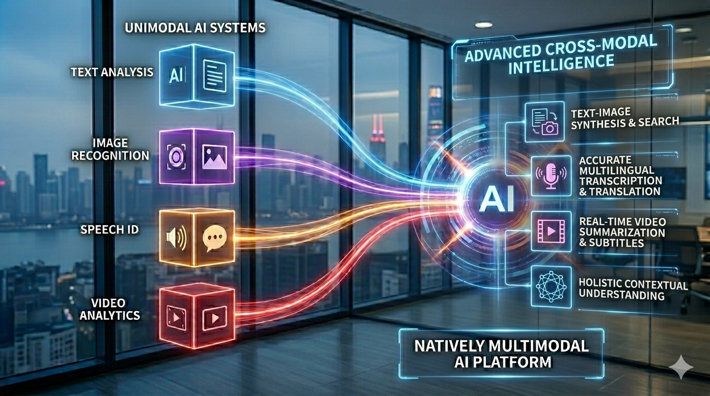
許多企業導入AI後,往往陷入一種窘境:文字分析用一套系統,影像辨識換一套,語音識別又是另一套。工具越裝越多,卻越來越難整合,資料孤島林立,維護成本不斷墊高。而多模態AI(Multimodal AI)的崛起,正在改寫這種局面。
試想這樣的場景:開完一場兩小時的會議,AI同時聆聽錄音、讀懂投影片、辨識白板上的手繪圖表,會後幾分鐘內自動產出結構化摘要與待辦清單,即為而是多模態AI在企業協作工具中逐漸落地的真實應用。當AI不再只靠「讀文字」來理解世界,企業的AI部署邏輯也正面臨翻轉。
什麼是多模態AI?
傳統AI模型通常只能處理單一類型的資訊:文字模型讀文字,圖像模型看圖片,語音模型辨識聲音。多模態AI打破了這道隔閡,讓單一模型能夠同時接收文字、圖像、音訊、影片,並融合多種訊號進行綜合推理與回應,更接近人類「眼耳並用」的思考方式。
新一代模型:AI全面「多感官化」
2025年下半年起,主要AI廠商推出的旗艦模型已幾乎全面具備原生多模態能力。Meta的Llama 4在訓練階段即整合影像與文字,並以開放權重的形式支援企業私有化部署;OpenAI的GPT-5家族在視覺理解與多模態推理能力亦大幅提升,官方API規格以文字與圖像輸入為主,context window達400K~1M token(依版本);Google的Gemini 2.5系列則以多模態視覺推理著稱,原生支援文字、圖像、音訊與影片的統一輸入,並透過Search Grounding能力整合外部即時資訊。
從市場規模看,多模態AI市場在2025年已達約30億美元,預計2026年將成長至38.5億美元,2031年更可望突破135億美元(Mordor Intelligence, 2026)。Gartner亦預測,到2027年,40%的生成式AI解決方案將具備多模態能力,顯示這波浪潮正快速向企業滲透。
表1、主要多模態AI模型能力比較
模型 | 開發商 | 支援模態 | 主要特色 |
GPT-5 | OpenAI | 文字、圖像 | 400K~1M context(依版本),推理能力持續強化 |
Gemini 2.5 Pro | Google DeepMind | 文字、圖像、音訊、影片、PDF | 視覺推理、Search Grounding 整合 |
Llama 4 | Meta | 文字、圖像 | 開放權重、可私有化部署 |
Claude 4 Opus | Anthropic | 文字、圖像、視覺文件(PDF/圖表) | 長脈絡理解、文件分析 |
資料來源:整理自OpenAI、Google DeepMind、Meta、Anthropic官方文件
企業落地:三大核心應用場景
一、製造業品管與預測維護
多模態AI整合產線攝影機影像、IoT振動感測數據與過往維修記錄,即時進行品質缺陷分類,並同步建議根本原因與工單處理方案。部分實證案例顯示,導入AI驅動預測性維護後,可顯著降低非計畫停機與急修比例,但實際成效高度取決於設備類型、資料品質與維運流程成熟度。
二、企業文件處理
過去需要多個獨立系統才能完成的文件審閱/擷取、報告摘要等任務,現在可透過單一多模態平台一次處理。不論是掃描的PDF文件、圖表截圖,還是口頭說明,系統均能整合理解並輸出結構化資訊。採用多模態統一平台有機會減少多套系統的整合與維護負擔,降低資料孤島與重複建置的隱性成本,但實際節省幅度仍須依企業既有架構與治理成本評估。
三、客戶服務與語音互動
多模態AI能同時理解客戶語音、畫面截圖與文字描述,使客服系統從單純「回答問題」進化為「主動解決問題」。系統可識別客戶情緒、定位問題根源,並跨越溝通渠道(電話、線上聊天、電子郵件)提供一致性的解決方案,大幅提升首次解決率與客戶滿意度。
對企業AI部署策略的啟示
對於正在規劃或評估AI解決方案的企業而言,多模態能力的普及帶來了策略上的轉折點。過去「為不同任務選擇不同AI工具」的思維,正逐漸演進為「以多模態統一平台整合跨任務需求」。根據市場研究機構IDC預測,臺灣企業正加速跨入新型AI與組合式架構,帶動台灣人工智慧平台(AI Platform)與相關資訊服務支出迎來快速增長,其中生成式AI的核心部署將高度集中於金融、製造、醫療三大產業。對軟體顧問與解決方案規劃者而言,理解多模態能力的邊界與適用場景,將成為協助客戶做出正確AI投資決策的關鍵能力。
FIND觀點
多模態AI的崛起,不只是技術層次的進化,更是企業思維方式的轉型契機。筆者觀察,目前許多企業在導入AI時仍習慣以「單點工具」思維選型,針對不同任務部署不同的AI系統,導致整合成本高、資料孤島嚴重。隨著多模態平台日趨成熟、成本持續下降,建議企業在下一輪AI採購評估時,將多模態能力列為重要衡量指標,提前思考如何以統一的感知架構取代既有的碎片化工具組合,為未來的AI應用奠定更靈活的基礎。
封面圖片來源:本文作者以AI生成
參考資料來源:
1.Global Market Insights (2024). Multimodal AI Market Size & Share - Industry Report 2025-2034. https://www.gminsights.com/industry-analysis/multimodal-ai-market
2.Gartner (2024). Gartner Predicts 40% of Generative AI Solutions Will Be Multimodal by 2027. https://www.gartner.com/en/newsroom/press-releases/2024-09-09-gartner-predicts-40-percent-of-generative-ai-solutions-will-be-multimodal-by-2027
3.OpenAI (2025). Models Overview - GPT-5 Family. https://platform.openai.com/docs/models
4.Google DeepMind (2025). Gemini 2.5 Pro Technical Overview. https://deepmind.google/technologies/gemini/
5.Meta AI (2025). The Llama 4 herd: Natively multimodal AI. https://ai.meta.com/blog/llama-4-multimodal-intelligence/
6.Anthropic (2025). Claude 4 Opus Model Overview. https://www.anthropic.com/claude
7.VyzerCorp (2026). Multimodal AI in 2026: Use Cases, Benefits & Enterprise Impact. https://www.vyzercorp.com/blog/multimodal-ai-in-2026-use-cases-benefits-enterprise-impact
8.SuperAnnotate (2026). What is multimodal AI: Complete overview 2026. https://www.superannotate.com/blog/multimodal-ai
9.IDC (2025). Taiwan AI Platform Market Outlook. IDC Insights on AI Platform adoption trends.
10.Mordor Intelligence (2026). Multimodal AI Market Size, Share, Trends & Insights Report. https://www.mordorintelligence.com/industry-reports/multimodal-ai-market
王勝弘
2026-05-28
