

分享
'%3e%3cpath%20d='M12.8276%205.73367L12.5096%208.74976H10.0987V17.4995H6.47736V8.74976H4.67285V5.73367H6.47736V3.91783C6.47736%201.46481%207.49748%200%2010.3973%200H12.807V3.01609H11.299C10.1739%203.01609%2010.0987%203.44123%2010.0987%204.22665V5.73367H12.8276Z'%20fill='%2398A2B3'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_162_3194'%3e%3crect%20width='17.4995'%20height='17.4995'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M6.91992,6l14.2168,20.72656l-14.9082,17.27344h3.17773l13.13867,-15.22266l10.44141,15.22266h10.01367l-14.87695,-21.6875l14.08008,-16.3125h-3.17578l-12.31055,14.26172l-9.7832,-14.26172z'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
AI 與古典音樂的交會:Symphonia 近即時音源分離技術實踐與啟示(下)

在上篇文章中,我們探討了古典與交響音樂之音源分離(Music Source Separation, MSS)問題的挑戰,指出其在資料稀缺、音樂結構複雜及空間混響等層面仍屬開放議題。為回應這些挑戰,本研究提出一個針對古典音樂特性設計的近即時音源分離系統(Near Real-Time Orchestral Music Source Separation System)。
本研究以時頻導向(Spectrogram-Based)方法為核心,自主研發 CNNSpecOnly 架構,融合因果卷積神經網路(Causal CNN)、時頻交叉注意力機制(Time-Frequency Cross-Attention)與 U-Net 型編解碼器(Encoder-Decoder)設計。與傳統採用雙向上下文(Bidirectional Context)的模型不同,本系統在時間維度上採取嚴格時間因果性(Strict Temporal Causality)原則,限制模型於推論過程中僅能利用當前及過去的時間訊號,完全不依賴未來資訊,以確保即時串流與互動應用中的穩定性與一致性。
在架構層面上,任一時間點的輸出僅依賴當前與過去訊號,該原則不僅應用卷積層感受野(receptive field)的設計,亦延伸至交叉注意力機制(Cross-Attention)與跳接結構(Skip Connections)的時間對齊策略,使整個網路於各層級皆嚴格遵守因果性約束。
在此基礎下,模型透過多層時頻特徵融合(Multi-Scale Time-Frequency Feature Fusion)與跨頻帶注意力(Cross-Band Attention)建模頻域間的諧波關聯,使其在保持因果與低延遲條件下,仍能捕捉音樂結構與多聲部互動,實現高解析度、自然且穩定的音源分離。
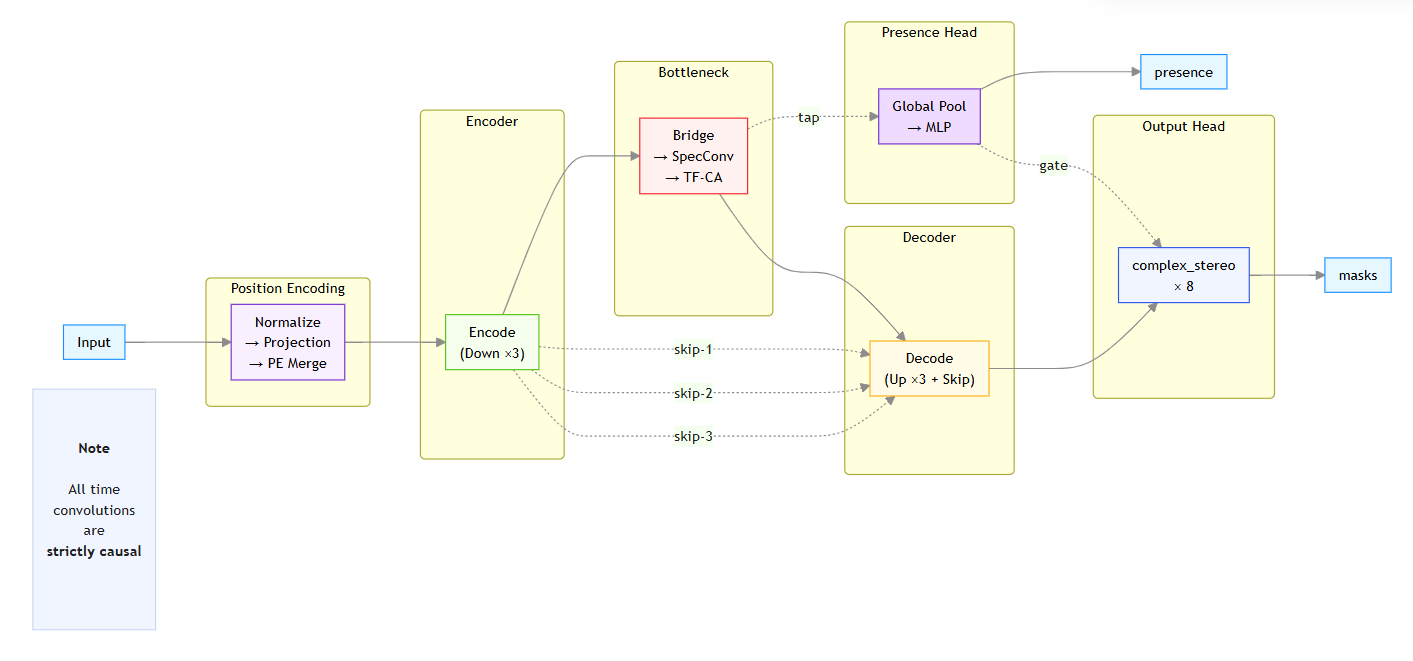
圖1:CNNSpecOnly 架構圖
資料來源:本文作者自行繪製
模型針對八種主要管弦樂器 小提琴(Violin)、大提琴(Cello)、單簧管(Clarinet)、長笛(Flute)、小號(Trumpet)、法國號(Horn)、低音提琴(Double Bass)與定音鼓(Timpani)進行訓練,並於 STFT 域中以複數頻譜遮罩(Complex Mask)同時預測幅度與相位,以提升音質自然度與時間一致性。系統採用重疊加法(Overlap-Add, OLA)與淡入淡出(Fade-In/Fade-Out)機制進行分段推論,可在短片段處理下平滑拼接音訊,有效降低邊界失真。
此外,模型設計支援多種遮罩模式(Mask Modes)與存在性預測頭(Presence Heads)以應對樂器缺席情況,並整合諧波位置編碼(Harmonic Frequency Positional Encoding)與可學習頻率嵌入(Learnable Frequency Embedding),以強化模型對弦樂與管樂頻譜結構的辨識能力與分離精度。整體架構在保留嚴格時間因果與低延遲特性的同時,兼顧音樂結構理解與聲音自然度,特別適用於古典音樂場景下的近即時音源分離應用。
本研究以國家交響樂團(NSO)提供之實際多樂器錄音素材為核心資料來源,涵蓋8種主要管弦樂器。所有錄音皆以 48 kHz 採樣率與雙聲道(Stereo)方式進行,每種樂器約錄製1小時,總計約8小時原始音軌。研究者親自進行資料前處理,針對錄音中非演奏聲音(例如打噴嚏、談話、翻譜、腳步聲、打拍子聲,以及演奏間的靜音或環境雜音時段等)進行檢查與移除,以確保音訊品質與訓練資料的一致性。
為提升模型的魯棒性(Robustness)與泛化能力(Generalization Capability),本研究採用了多種資料增強技術與真實音場模擬流程,以提升模型在不同錄音條件與樂器組合下的穩定性與適應性。
在本研究的脈絡中,魯棒性指模型能在面對輸入變異(如錄音品質、混響條件、樂器音量比例差異、背景噪聲等)時,仍維持穩定且可預期的分離效果;亦即即使實際輸入訊號與訓練樣本分布存在差距,模型仍能產生具音樂一致性(Musical Consistency)的輸出結果。
而泛化能力則反映模型從訓練資料中學得的音樂與聲學模式能否有效遷移至未見過的情境,例如新的樂曲風格、不同編制的管弦樂組合、或異於訓練環境的錄音空間。具良好泛化性的模型不僅能在實驗數據上表現優異,亦能於真實演奏與即時應用中維持高準確度與自然感。
為此,本研究採用了多種資料增強策略,包括音量變化(Gain Perturbation)、時間偏移(Temporal Shift)、混響模擬(Reverberation Simulation)、以及音高與速度伸縮(Pitch and Time-Stretching)等方式,以生成多樣化的音訊樣本,模擬演奏過程中可能出現的動態變化與空間聲學條件。此外,透過不同樂器組合進行混音合成(Mixture Generation),系統可模擬多種聲部交互與配器比例,增加模型對複雜音場的辨識能力。
同時,為貼近真實演奏場域的聲學條件,研究者亦於實際音樂廳環境中進行收音測試,觀察真實空間中的聲音擴散、殘響延遲與頻譜平衡特性,並嘗試多種混音測試(Mixing Experiments),以分析不同音量比例、樂器組合與空間響度設定下的聲場差異。此過程有助於評估模型對真實音場響應的適應性,並提供混音與聲學特性之間的實證參考,用以優化後續的資料前處理與模型訓練策略。最終建立約十萬筆、每筆長度二秒(總時長約二十萬秒,資料量約4TB)的自建訓練資料集,涵蓋多樣化的樂器組合與音場條件,作為模型訓練與評估的核心基礎。
本研究的主要貢獻在於將深度學習音源分離技術導入古典與交響音樂場景,提出一套具時頻一致性(Time-Frequency Consistency)、結構感知(Structure-Aware)與低延遲特性(Low-Latency Capability)的近即時音源分離框架。該系統能有效分離多種樂器聲源,提升音質自然度與空間清晰度,展現深度模型於古典音樂場域的可行性與實用潛力。
此外,本研究亦自建一套大規模古典音樂多軌資料集(Large-Scale Orchestral Multi-Track Dataset),涵蓋八種主要管弦樂器(小提琴、大提琴、單簧管、長笛、小號、法國號、低音提琴、定音鼓),共計約十萬筆。
經實驗評估,系統於八種樂器的測試資料上可達平均約 4.5 dB 的信號失真比(Signal-to-Distortion Ratio, SDR)。此數值顯示模型能有效降低背景混疊與交叉洩漏(Bleeding)現象,分離後的樂器訊號仍能保有主要聲部的清晰度與結構完整性。換言之,4.5 dB SDR 代表輸出訊號中真實樂器能量約為殘留雜訊的 2.8 倍,屬於中品質分離水準,足以支撐後續的音訊分析、重混(Remix)或互動應用。
然而,在非樂器聲源(如人聲對話、觀眾聲或低頻背景噪音)混入的情境中,模型仍可能出現誤分或誤歸類(Mis-Separation/Misclassification)現象。例如,在部分輸出結果中,樂器音軌中仍夾雜人聲片段或環境聲,模型誤將這些非樂器成分判定為大提琴或低音提琴的低頻部分。
此外,當輸入音訊中出現過高音量或瞬時強音(Over-Amplitude / Transient Peaks)時,模型亦可能因動態範圍(Dynamic Range)超出訓練分佈而產生誤判,將強奏樂器的能量誤分散至其他音軌,例如將銅管或定音鼓的強音誤混入弦樂聲部中。此問題主要源自於現有資料集中非樂器聲源未被標註或歸類,以及高動態音訊樣本不足,導致模型在訓練時無法充分學習對應特徵,進而產生偏向常見樂器的先驗(Prior)誤差。
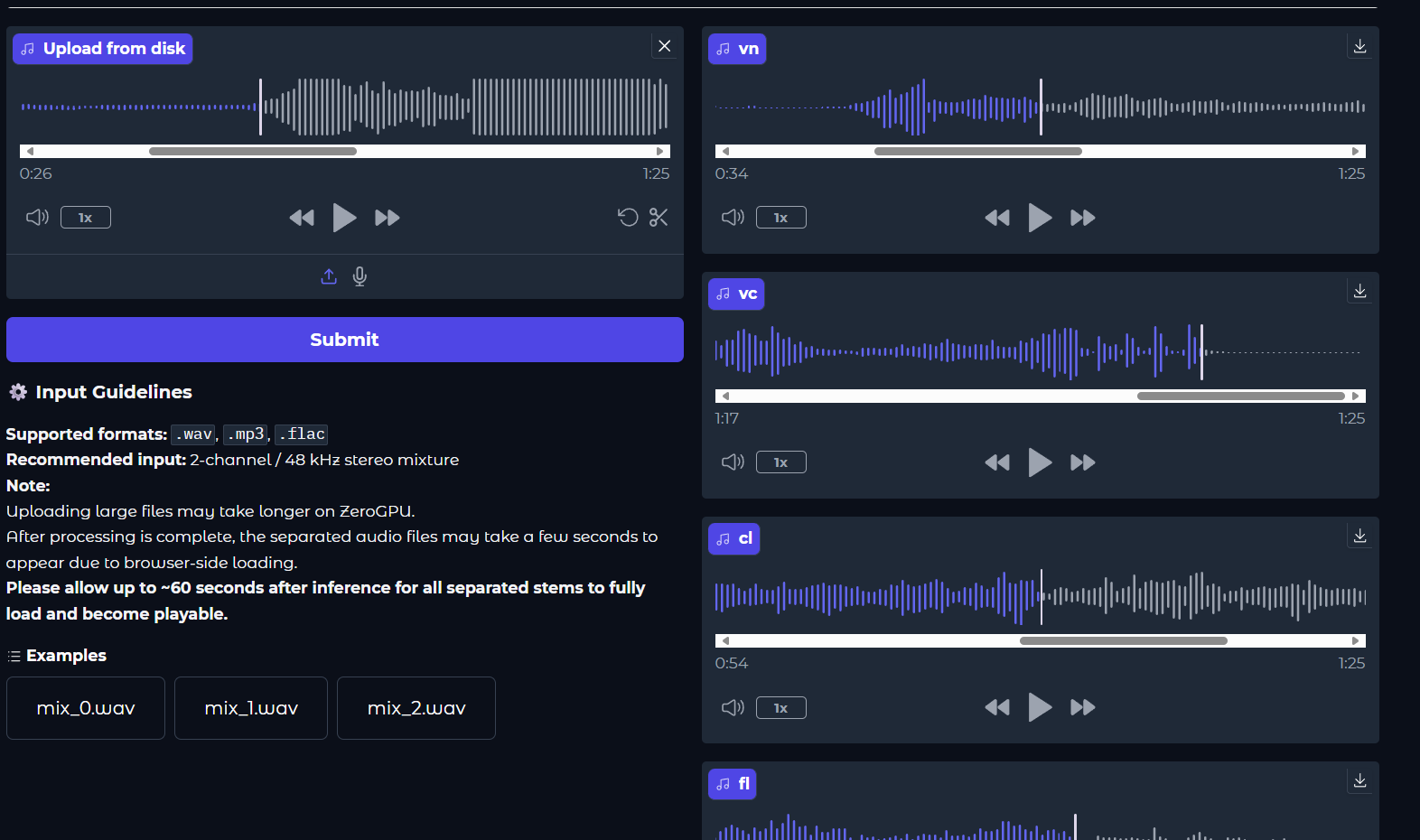
圖2:古典音樂源分離Demo
資料來源:
Symphonia — Near Real-Time Orchestral Music Source Separation
此系統已於 Hugging Face Spaces 平台上提供互動式展示與實證:Symphonia — Near Real-Time Orchestral Music Source Separation(https://huggingface.co/spaces/YWYG/symphonia)。使用者可即時上傳音訊片段,體驗八軌分離、音源可視化與多樂器輸出結果,展示本系統在古典音樂場景中的實際效能與應用潛力。
整體而言,這反映出古典音樂聲源分離模型在「非樂器聲源辨識」、「高音量動態響度處理」與「多類聲源混合環境」下仍具挑戰性。未來研究可透過補充並標註非樂器聲源資料(如人聲、觀眾反應、環境噪音等),同時納入高動態範圍與極端音量樣本以擴充訓練集多樣性,並結合語音抑制與背景噪音建模模組,以進一步提升模型於真實演出環境中的魯棒性與分離精準度。
綜上所述,本研究成果可作為未來助聽器輔助聆聽、個人化混音與互動音樂系統的技術基礎,使聽力受損者與一般聽眾皆能以更靈活、可調式的方式重新體驗古典音樂的豐富層次與動態表現,並為「音樂無障礙化(Accessible Music Technology)」之發展提供具體的技術方向與實作範例。
封面圖片來源:本文作者自行拍攝
參考資料來源:
World Health Organization. (2024, March 3). Deafness and hearing loss. World Health Organization. https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss (Accessed: November 4, 2025)
Roa-Dabike, G., Cox, T. J., Barker, J. P., Akeroyd, M. A., Bannister, S., Fazenda, B., ... & Whitmer, W. M. (2025). Source Separation of Small Classical Ensembles: Challenges and Opportunities. arXiv preprint arXiv:2505.17823.
Araki, S., Ito, N., Haeb-Umbach, R., Wichern, G., Wang, Z. Q., & Mitsufuji, Y. (2025, April). 30+ years of source separation research: Achievements and future challenges. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE.
National Symphony Orchestra (Taiwan). (n.d.). Official website of the National Symphony Orchestra (NSO). National Performing Arts Center. https://www.npac-nso.org/zh/(Accessed: November 4, 2025)
YWYG. (2025). Symphonia — Near Real-Time Orchestral Music Source Separation [Computer software]. Hugging Face Spaces. https://huggingface.co/spaces/YWYG/symphonia (Accessed: November 4, 2025)
Wang, C. H., Wang, C. C., Wang, J. Y., Jang, J. S. R., & Chu, Y. H. (2024, October). Improving Real-Time Music Accompaniment Separation with MMDenseNet. In 2024 27th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA) (pp. 1-6). IEEE.
Gusó, E., Pons, J., Pascual, S., & Serrà, J. (2022, May). On loss functions and evaluation metrics for music source separation. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 306-310). IEEE.
Stöter, F. R., Uhlich, S., Liutkus, A., & Mitsufuji, Y. (2019). Open-unmix-a reference implementation for music source separation. Journal of Open Source Software, 4(41), 1667.
Défossez, A., Usunier, N., Bottou, L., & Bach, F. (2019). Demucs: Deep extractor for music sources with extra unlabeled data remixed. arXiv preprint arXiv:1909.01174.
Hennequin, R., Khlif, A., Voituret, F., & Moussallam, M. (2020). Spleeter: a fast and efficient music source separation tool with pre-trained models. Journal of Open Source Software, 5(50), 2154.
Li, B., Liu, X., Dinesh, K., Duan, Z., & Sharma, G. (2018). Creating a multitrack classical music performance dataset for multimodal music analysis: Challenges, insights, and applications. IEEE Transactions on Multimedia, 21(2), 522-535.
Bittner, R. M., Salamon, J., Tierney, M., Mauch, M., Cannam, C., & Bello, J. P. (2014, October). Medleydb: A multitrack dataset for annotation-intensive mir research. In Ismir (Vol. 14, pp. 155-160).
楊育維
2025-12-03
