

分享
'%3e%3cpath%20d='M12.8276%205.73367L12.5096%208.74976H10.0987V17.4995H6.47736V8.74976H4.67285V5.73367H6.47736V3.91783C6.47736%201.46481%207.49748%200%2010.3973%200H12.807V3.01609H11.299C10.1739%203.01609%2010.0987%203.44123%2010.0987%204.22665V5.73367H12.8276Z'%20fill='%2398A2B3'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_162_3194'%3e%3crect%20width='17.4995'%20height='17.4995'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M6.91992,6l14.2168,20.72656l-14.9082,17.27344h3.17773l13.13867,-15.22266l10.44141,15.22266h10.01367l-14.87695,-21.6875l14.08008,-16.3125h-3.17578l-12.31055,14.26172l-9.7832,-14.26172z'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Meena:Google發表目前最符合人類真實的對話情境的開放領域型對話機器人
對話機器人
對話機器人一直是人工智慧十分重要的研究議題,常見的對話機器人主要可分為任務導向型(Task-Oriented)以及開放域型(Open-Domain)兩種。任務導向型對話機器人往往用於回答特定領域問題或執行特定任務,例如:線上客服機器人及線上訂票機器人等。至於開放領域型對話機器人則沒有限制對話的主題與內容,如微軟小冰和蘋果Siri等。
Google Meena
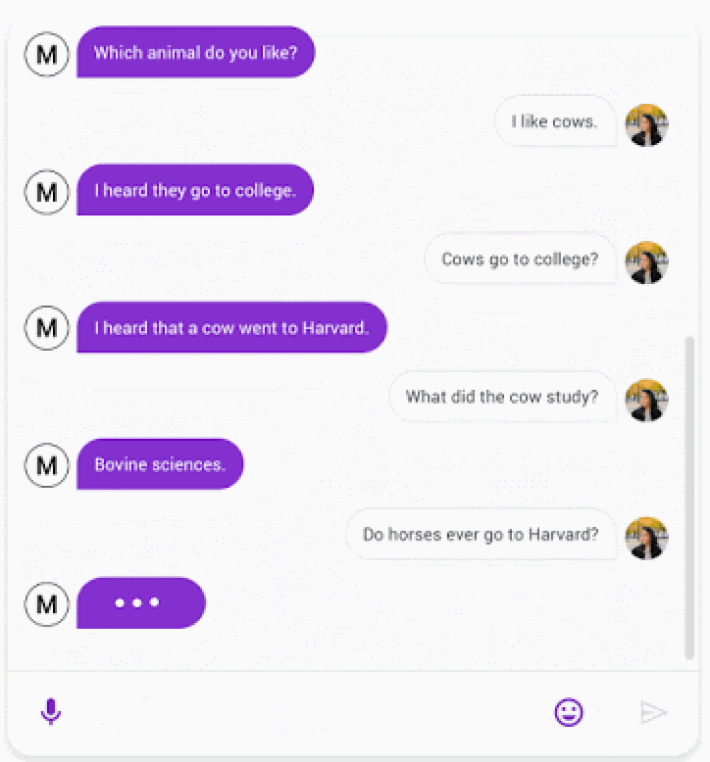
目前在開放領域的對話機器人的發展上仍有許多不足之處,例如沒有考慮上下文關係以致於產生沒意義的對話或是對話前後不一的情況。2020年初,Google發表了一個開放領域型對話機器人Meena針對上下文理解有了突破性的發展。Google宣稱Meena較現有的開放領域對話機器人在回答問題上可以更具體也更清楚合理,更符合人類真實上下文理解的對話情境,其對話介面如圖1所示。與此同時,為了驗證Meena的效能,Google亦提出一套以人類評分為基礎的評價指標「Sensibleness and Specificity Average (SSA)」做為開放領域型對話機器人的評估標準。
圖1:Meena與人類對話介面。 (圖片來源:Google AI Blog)
Meena的訓練架構
Google宣稱Meena最特別的突破點在於其上下文理解能力,在Meena訓練模型中,包含1個編碼模組用以處理上下文理解和13個解碼模組用以產生適當的回應,這些模組共有高達26億個參數,是GPT-2模型的1.7倍。在訓練文本上,Google由公共領域的社群媒體對話過濾出341GB文本來進行連續型多輪對話訓練,訓練資料量為GPT-2的8.5倍。
Sensibleness and Specificity Average (SSA)
為了驗證Meena的開放領域型對話能力,Google提出透過人類評分的對話機器評價指標SSA。該指標以真人感受為評分標準,透過測試者在每次對話後針對機器人該輪的回答「是否有意義」以及「是否具體」進行評分。綜合兩者的平均值,即為SSA。
實驗結果驗證
植基在SSA評估標準下,Google以群眾外包方式將Meena與Mitsuku、Cleverbot、DialoGPT及XiaoIce四個知名的開放領域型對話機器人進行比較。實驗結果如圖2所示,根據Google實驗結果,Meena的SAA達到79%,直逼人類的86%,領先第二名的Mitsuku達23%。由此可知,Meena較目前知名的開放領域型對話機器人有著接近人類真實對話的表現。
圖2:Meena與知名的開放領域型對話機器人比較結果。(圖片來源:Google AI Blog)
楊偉楨
2020-02-20
