

分享
'%3e%3cpath%20d='M12.8276%205.73367L12.5096%208.74976H10.0987V17.4995H6.47736V8.74976H4.67285V5.73367H6.47736V3.91783C6.47736%201.46481%207.49748%200%2010.3973%200H12.807V3.01609H11.299C10.1739%203.01609%2010.0987%203.44123%2010.0987%204.22665V5.73367H12.8276Z'%20fill='%2398A2B3'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_162_3194'%3e%3crect%20width='17.4995'%20height='17.4995'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
'%3e%3cpath%20d='M6.91992,6l14.2168,20.72656l-14.9082,17.27344h3.17773l13.13867,-15.22266l10.44141,15.22266h10.01367l-14.87695,-21.6875l14.08008,-16.3125h-3.17578l-12.31055,14.26172l-9.7832,-14.26172z'%3e%3c/path%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
階層式預訓練:以自監督學習改良自監督學習
【自監督式學習】
在人工智慧領域中,機器學習是十分重要的一個範疇。在機器學習中最為廣泛使用的為監督式學習(supervised learning),其為透過人工標記的資料給與機器學習正確的答案並作為推論的依據。然而透過監督式學習方式需要大量耗費人力與時間進行人工標記,將會拖延技術導入的時程。為了突破這樣的限制,因而產生了自監督學習。自監督學習主要透過自監督任務(Pretext)由大量未經人工標記資料中自我建構監督資訊,並通過自我建構的監督資訊進行預訓練(Pretrain),從而使所訓練出的預訓練模型能承載具有價值的語義表徵或結構意義等,並且能夠有益於下游任務(Downstream task)。有了預訓練模型後,對於新的下游任務,僅需要少量人工標記資料來對於預訓練模型進行微調(Finetune),即可得到一個能適應新的下游任務的訓練模型。
【階層式預訓練】
在傳統的作法上,預訓練的過程多是採用大量未經人工標記通用領域資料集透過自監督任務進行訓練。然而這樣的預訓練方式雖然可以得到一個高泛用性的預訓練模型,但對於特定領域下游任務卻無法取得較佳的效果。因此有學者提出針對特定領域的下游任務選擇該領域資料集進行預訓練,但是此方案又會面臨特定領域資料量往往不足以透過自監督學習得到良好的語義表徵或結構意義,因而產生一個無法符合期待的預訓練模型。為了解決這個問題,階層式預訓練(Hierarchical Pretraining)就應運而生。在階層式預訓練中,首先如傳統作法使用大量未經人工標記通用領域資料集進行預訓練,而後再使用與根據目標下游任務選擇特定領域資料集進行預訓練,最後再使用目標下游任務的訓練資料集進行預訓練。透過階層式預訓練所得到的預訓練模型,將會有適用特定領域的目標下游任務的效果,又無需大量的特定領域資料。以下我們將針對階層式預訓練進行較深入的介紹。
資料來源:自行繪製
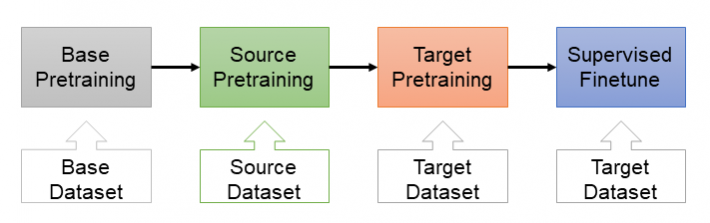
圖1、階層式預訓練架構圖
【階層式預訓練步驟】
如圖1所示,階層式預訓練主要分成三個步驟:基礎預訓練(Base Pretraining)、源預訓練(Source Pretraining)以及目標預訓練(Target Pretraining),最後再將所得到的預訓練模型透過下游任務的目標資料集進行監督式微調(Supervised Finetune)。以下將分別介紹上述步驟。
- 基礎預訓練:基礎預訓練為初始預訓練步驟,其使用大量通用領域資料集,又稱基礎資料集 (Base Dataset)從頭開始進行預訓練,取得基礎預訓練模型。
- 源預訓練:給定一個基礎預訓練模型,根據下游任務選擇特定領域資料集,又稱源資料集(Source Dataset)進行訓練,取得源預訓練模型。一般而言,源資料集資料量小於基礎資料集,但與目標下游任務的訓練資料集高度相關。
- 目標預訓練:植基源預訓練模型,使用目標下游任務的訓練資料集執行自監督預訓練,取得目標預訓練模型。
- 監督式微調:最後,透過監督式微調對於目標預訓練模型進行遷移式學習,得到能適應目標下游任務的最終訓練模型。
【結語】
自監督學習近年已經逐漸成為機器學習的主流,也已經成功被應用至許多領域上,如文字處理、影像處理等,證明自監督學習有著極高的泛用性。階層式預訓練則使得自監督學習所得到的預訓練模型能夠更符合下游任務特性,提高下游任務的有效性,可以預期階層式預訓練將會逐漸成為自監督學習產生預訓練模型的重要關鍵技術。
- https://arxiv.org/abs/2103.12718
- https://www.gushiciku.cn/pl/pwX2/zh-tw
- https://iter01.com/547887.html
楊偉楨
2021-09-17
